|
本文获2020年“中国市场研究行业‘分众传媒’优秀论文奖”一等奖。原文题目为《大数据概率抽样框的编制及其统计推断》,作者系CTR付晓东、王霄。
提要:大数据具有数据量庞大、多源异质、信息稀疏、对总体涵盖不全等特点,直接基于大数据的存储和分析从而进行消费者洞察,必然会面临数据存储压力,复杂的计算以及难以精确反映目标总体信息等问题。大数据背景下,随机抽样仍然是解决这些问题最直接、最有效的方法,因此,大数据概率抽样框的编制对实现全方位消费者洞察具有不可或缺的理论和应用价值。
研究背景
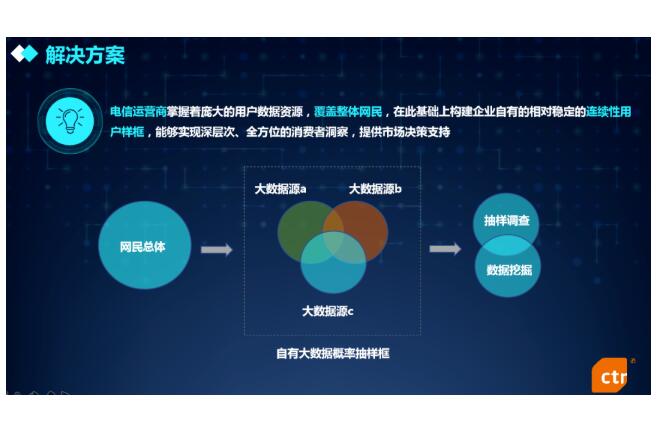
随着互联网技术的发展,基于通信、社交、网络购物等各方大数据来源具有几亿的用户量,已经覆盖了大多数网民。目前通过单一来源大数据并不能完整观测到目标总体的特征,而且各方大数据之间通常存在着不可逾越的数据壁垒。因此,CTR考虑在整个用户框架下构建以运营商用户数据为主,包含多个互联网平台的相对稳定的连续性大数据抽样框,最大限度地涵盖网民总体信息,尽量还原网民总体特征。
研究方法
关于抽样框规模,国家统计局除10年一度的全国人口普查外,每5年进行一次1%抽样调查,抽样规模超过1000万人,对应抽样误差为0.26‰,获得了精确度非常高的全国人口、经济等各类指标的估算结果。
据此,大数据抽样框的编制规模大约为千万级,超过9.4亿总体网民的至少1%抽样。CTR基于人口普查和统计年鉴、中国互联网发展状况统计报告(CNNIC)、CTR大型连续性网络调查等数据来源,完成中国各城市网民规模和分布情况的推算,进而严格按照网民分布结构,遵循概率原则在运营商数据资源中随机抽样,建立与网民总体高度贴合的样框数据,在大数据抽样框中进行抽样调查和数据挖掘,实现深层次、全方位的消费者洞察,藉此为市场决策提供策略支持。为防止样本老化和流失,在每年的第一次抽样调查之前进行约20%的样本轮换。
实践应用
迄今为止,CTR在针对大数据抽样框进行大量的理论研究、夯实方法论基础的同时,也已逐步将其转化为市场研究的实际应用,完成了各类场景下抽样调查和数据挖掘的若干项目实践。整合电信运营商、大型网站、在线样组等数据资源基础上编制的自有大数据概率抽样框在实际应用中优势凸显。
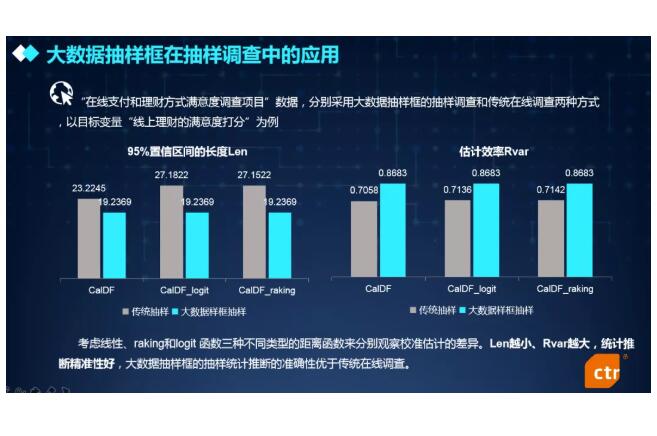
为了验证基于大数据概率抽样框的抽样调查相较于传统在线调查能够提升总体推断的准确性,CTR已经进行了产品满意度调查、消费者态度和行为研究、新产品上市研究等若干抽样调查项目的模拟和实际测试。大数据抽样框校准估计量对应的Rvar 较高,置信区间长度Len较短,即大数据抽样框的抽样参数估计的效率较高。由此说明,基于大数据抽样框的抽样统计推断的准确性优于传统在线调查。
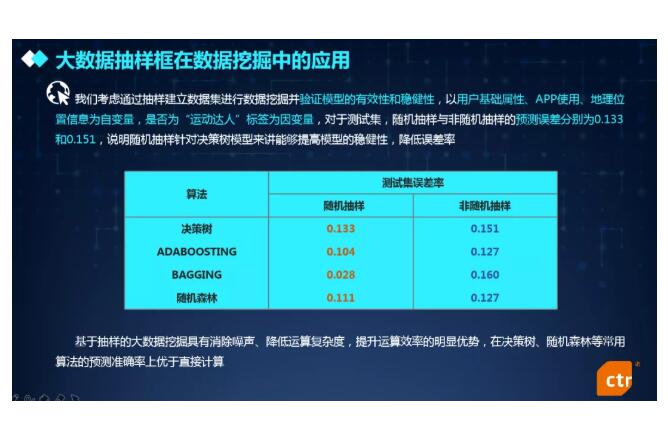
利用大数据建模时,除了缺乏先验信息,分布未经验证之外,数据本身的属性也会成为统计建模和分析的难题,如高维度、时间序列特性、变量间的复杂关系等等,都是亟待解决的问题。因此,CTR通过在大数据样框中抽样建立较小的数据集进行数据挖掘,并验证模型的有效性和稳健性。如下图,可以看到四种常用的机器学习算法在抽样数据集中的预测误差率较小,由此说明,抽样技术在数据挖掘中的表现均优于直接基于大数据的计算,随机样本在大数据分析过程中仍然具有很重要的应用价值。
研究的应用价值与优势
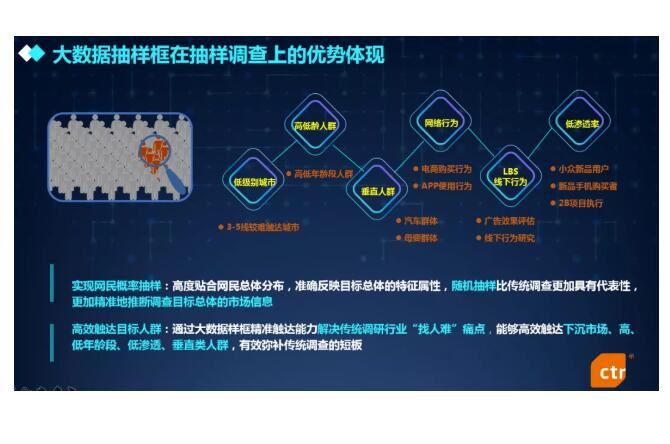
对于抽样调查来说,主要体现在最大化地涵盖抽样调查的目标群体,实现网民概率抽样,相比传统调查更加具有代表性,更加精准地推断调查目标总体的市场信息。
另外,通过大数据抽样框精准触达能力解决了传统调研行业“找人难”的痛点,能够高效触达包括下沉市场、高低年龄段、市场低渗透率、垂直类人群等传统市场调查难以触及的目标人群,有效弥补了传统调查的短板,在创新执行方法方面有所突破。
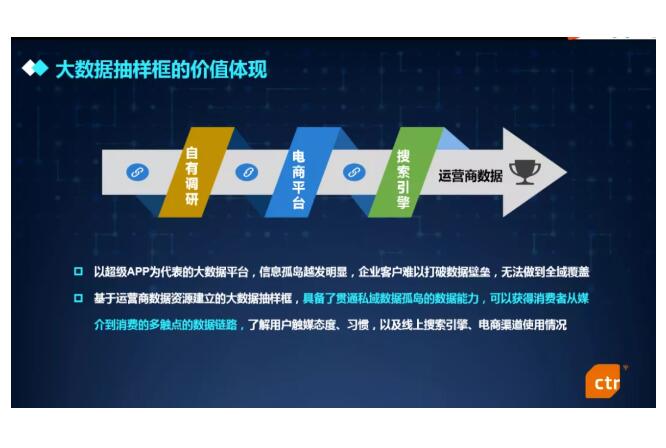
在以运营商数据为基础建立的大数据抽样框,实质上提供了一套可持续的用户行为观测的数据环境。以超级APP为代表的大数据平台,信息孤岛越发明显,难以打破数据壁垒,无法做到全域覆盖。运营商数据更显水平化,基于运营商数据的用户样框具备全域用户洞察的数据能力,可为客户提供基于DPI流量数据的用户媒体接触习惯,乃至热播剧、某些KOL及广告的触达效果,以及京东、阿里等线上电商渠道使用情况的态势掌握,提供最全面最丰富的消费者洞察,为制定最佳数字化营销方案提供策略支持。
总结和展望
基于大数据概率抽样框的编制设计,探究了大数据背景下新的抽样调查和大数据分析方法。大数据概率抽样框的代表性和总体推断的准确性均优于传统在线抽样调查的非概率样本。
基于大数据抽样框的抽样技术在数据挖掘方法中的应用,有效地节约存储空间和降低运算复杂度,提升模型的准确率。未来,基于多来源大数据抽样框的搭建,以及在保护用户隐私情况下,大数据抽样框与其他私域大数据的融合贯通,将为全域消费者洞察带来更多的应用价值,也将成为未来努力探索的方向。
|